
2022년 11월 30일에 발표된 ChatGPT로 본격적인 AI 시대가 개막했다. 너무도 똑똑한 챗봇의 등장으로 2023년 인터넷은 온통 ChatGPT가 지배했다고 해도 과언이 아닐 것이다. 그리고 이 기조는 2024년까지 이어졌고, 현재는 ChatGPT를 비롯한 다양한 LLM(Large Language Model)의 등장으로 생성형 AI 전성시대라고 해도 과언이 아니다. 그리고 이 중심에 NVIDIA가 있다.
사실 NVIDIA의 데이터 센터 GPU는 오랫동안 AI 연구에 있어 필수품으로 활용되어 왔지만, 이렇게 수요가 폭증한 것은 역시 ChatGPT 덕분이다. OpenAI의 ChatGPT가 NVIDIA A100 1만대 가량으로 학습했다는 사실이 알려지면서, NVIDIA의 데이터 센터 GPU에 대한 관심이 폭발적으로 증가했고, 급기야 2022년 10월에 출시한 NVIDIA A100의 후속, NVIDIA Hopper 아키텍처 기반의 GPU인 H100의 수요 역시 크게 증가한 것. 이에 힘입어 NVIDIA는 2023년 4월, GTC 2023에서 H100 라인업을 더욱 강화하기에 이른다. 그리고 그 해 AI GPU 시장은 NVIDIA H100이 지배했다. 이러한 이 기조는 2024년까지 이어졌다.
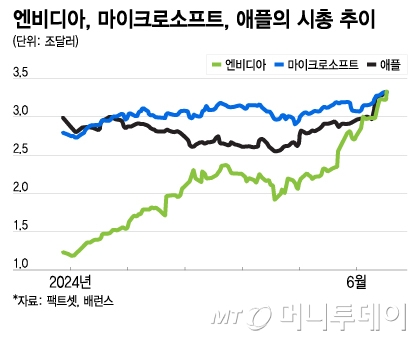
그 결과 NVIDIA는 2024년 6월, 미국 나스닥 시가총액 순위에서 Microsoft, Apple을 차례대로 제치고 1위에 등극한다. 생성형 AI, LLM에 대한 관심이 폭발하면서 AWS, Microsoft, Google, Meta와 같은 글로벌 빅테크 기업들 뿐만 아니라 많은 클라우드 사업자와 대기업들이 NVIDIA H100을 사재기 하는 수준으로 앞다투어 도입한 것이 주효했다. 2023년 6월에 사상 처음으로 시총 1조 달러를 기록한 NVIDIA는 H100 GPU의 엄청난 매출에 힘입어 2024년 2월 말에 2조 달러 돌파, 그리고 3개월 뒤인 6월 초에 3조 달러를 넘어서며 시총 1위에 오른 것이다.(하지만 지금은 다소 부침을 겪으며 3조달러 아래로 떨어졌고, 2025년 3월 12일 기준 3위를 기록 중이다.)
지난 Intel AI GPU 이야기에서 NVIDIA를 잠깐 언급하고 넘어갔었는데, 이번 글에서는 본격적으로 NVIDIA AI GPU 이야기를 해보려 한다. 그 첫 번째 순서는, AI GPU 시장을 90% 이상 점유하며 지배하고 있는 NVIDIA를 지금의 위치에 올려 놓은 일등 공신, H100이다. NVIDIA H100이 어떤 특징이 있고, 경쟁 제품들과 비교해 스펙은 어느 정도 수준이며, 이렇게 AI GPU 시장을 지배하게 된 이유가 무엇인지 살펴보겠다. 그리고 나서 최신 제품인 NVIDIA B200으로 넘어가면 될 것 같다. 그럼, H100부터 자세히 알아보자.
NVIDIA Hopper 아키텍처
NVIDIA는 H100의 H는 Hopper라는 아키텍처의 첫 머리글자다. 이전 세대의 GPU인 A100의 A는 Ampere라는 아키텍처다. NVIDIA 데이터 센터 GPU는 2007년에 처음 출시된 Tesla 아키텍처 기반 GPU를 1세대로 볼 경우 2011년 2세대 Fermi S2070, 2014년 3세대 Kepler K80, 2015년 4세대 Maxwell M60, 2016년 5세대 Pascal P100, 2018년 6세대 Volta V100, 같은 해 9월에 발표된 7세대 Turing, 2020년 8세대 Ampere A100에 이어 2022년 9세대 H100으로 진화해 왔다.

위 표는 NVIDIA 데이터 센터 GPU 모델 중 아키텍처 별 가장 고성능의 GPU만을 따로 정리한 것이다. NVIDIA GPU의 연산성능에 큰 영향을 끼치는 지표만 가져왔는데, 1세대와 비교해 9세대 H100은 CUDA Core 수 14배, 메모리 대역폭 5배, Single Precision 성능은 20배나 향상되었다. 특히 이전 8세대인 A100과 비교해도 CUDA Core 수 2배, 메모리 대역폭 30%, Single Precision 성능은 1.6배 향상되었는데, 다른 세대보다 특히 H100으로 진화하면서 이룬 성능 향상이 매우 큰 것을 알 수 있다.

이번에는 Tensor 코어가 장착된 GPU만 따로 정리했다. Tensor 코어는 2018년 Volta 아키텍처에서 처음 채용된 1세대 이후 2세대 Turing, 3세대 Ampere를 거쳐 Hopper에서 4세대로 진화했는데, 세대를 거듭할 때마다 성능이 향상되고 지원되는 정밀도 연산 종류도 증가하는 것을 확인할 수 있다. 게다가 1세대와 비교해 4세대에서는 오히려 코어 수가 줄었음에도 불구하고 성능이 대폭 향상되었는데, 아키텍처 설계 기술이 그만큼 향상된 것으로 이해해도 되겠다.
그렇다면, 이렇게 성능이 크게 향상된 Hopper 아키텍처는 어떤 특징을 가지고 있길래 이렇게 성능 향상폭이 큰 것일까? Hopper 아키텍처의 주요 특징 5가지를 알아보자.
트랜스포머 엔진

LLM(Large Language Model)이 학습해야 할 파라미터, 즉 AI 모델이 학습해야 하는 매개변수의 수는 수 천억개에서 수 조개에 이른다. 이렇게 많은 데이터 학습을 통해 자연스러운 자연어 모델을 개발하기 위해 사용되는 것이 딥러닝 모델 중 하나인 트랜스포머 모델인데, 널리 사용되는 트랜스포머 모델로 Google의 BERT, OpenAI의 GPT가 있다.
그럼 트랜스포머 엔진은 무엇일까? NVIDIA 데이터 센터 GPU에서 이러한 AI 학습 성능에 지대한 영향을 끼치는 것이 지난 2018년에 발표된 Volta 아키텍처 기반 GPU부터 추가된 Tensor 코어다. Tensor 코어는 TF32, FP64, FP16, INT8과 같은 부동 소수점 연산을 NVIDIA 컨슈머용 GPU, RTX 시리즈의 CUDA Core보다 훨씬 더 빠르고 정확하게 처리할 수 있는데, 이 Tensor 코어가 Hopper 아키텍처에서 4세대로 진화하면서 성능이 대폭 향상된 것이다. 이를 바탕으로 NVIDIA는 트랜스포머 모델이 더욱 빠르게 데이터를 학습시킬 수 있도록 도와주는 자체 트랜스포머 엔진을 H100에 새롭게 추가했고, 덕분에 H100은 LLM 모델 개발에 최적의 성능을 발휘할 수 있게 되었다.
NVLink, NVSwitch

NVLink는 NVIDIA GPU 여러개를 연결해 GPU들간의 데이터 전송 속도를 향상시켜 더욱 많은 병렬처리를 할 수 있도록 하는 기술이다. 2016년에 발표된 Pascal 아키텍처부터 채용되기 시작한 NVLink는 GPU 아키텍처와 함께 진화하며 Hopper 아키텍처에서 4세대로 진화했다. 성능 역시 세대를 거듭할 때마다 크게 향상되어 1세대 NVLink 대비 Hopper 아키텍처의 4세대 NVLink는 7배 이상의 높은 성능을 발휘한다.
NVLink는 다수의 GPU를 직접 연결시켜주는 기술인데, 이 NVLink를 서로 연결할 수도 있다. 이 때 필요한 것이 NVSwitch다. Hopper 아키텍처에서 3세대로 진화한 NVSwitch의 GPU 대역폭은 900GB/s로 1세대 300GB/s 대비 3배 향상되었다. NVSwtich는 최대 8개의 GPU 연결을 지원하기에 1개 서버 노드에 NVLink와 NVSwitch를 사용해 8개의 GPU를 장착할 수 있는 것이다. 이 서버들을 최대 32대까지 연결할 수 있는데, 이렇게 하면 총 256개의 NVIDIA H100 GPU를 사용한 엄청난 규모의 병렬처리 시스템을 구현할 수 있다.
컨피덴셜 컴퓨팅

AI 모델 학습을 위해 많은 데이터를 확보하는 것만큼이나 중요한 것이 보안이다. 열심히 학습시켜 추론한 결과물이 보안에 취약한 환경에 노출되어 유출되는 사태가 발생하면 큰일일테니 말이다. NVIDIA는 AI 서버의 CPU와 H100 GPU 사이의 데이터를 암호화해서 전송하며, 별도의 내장 방화벽을 통해 AI 워크로드를 완전히 격리되어 안전한하게 실행할 수 있는 환경인 TEE(Trusted Execution Environment)를 생성하는 컨피덴셜 컴퓨팅을 제공한다.
이 TEE에는 마치 제로 트러스트 보안 환경처럼 인증된 사용자만 접근할 수 있으며, AI 서버 노드 내의 단일 H100 GPU 또는 NVLink와 NVSwitch로 연결된 다중 H100 GPU에서 실행되는 AI 워크로드를 안전하게 보호한다. 인가되지 않는 사용자가 함부로 우리의 AI 모델과 데이터에 접근할 수 없도록 함으로써 AI 훈련 및 추론에 대한 기밀성을 확보할 수 있다는 것이 핵심이며, 이 컨피덴셜 컴퓨팅은 온프레미스 뿐만 아니라 클라우드, 엣지 환경에서도 동일하게 적용되어 H100 GPU가 사용되는 어디에서든 AI 모델과 데이터를 보호한다.
MIG(Multi-Instance GPU)

Hopper 아키텍처 기반의 강력한 성능을 자랑하는 H100 GPU가 여러대 연결된 단일 GPU 서버 노드를 데이터 과학자 혼자 독점하며 AI 모델 학습 및 추론에 활용할 수 있겠지만, 만약 기업 내에 데이터 과학자가 1명이 아닌 여러 명이라면? 그리고 이 여러 명의 데이터 과학자가 동시에 서로 다른 AI 프로젝트를 수행하고 있다면 어떨까? 각 데이터 과학자 별로 개별적인 GPU 서버 노드를 마련해줘야 할까?
이런 경우를 위해 NVIDIA는 MIG를 통해 GPU 리소스를 최대 7개로 분리해 사용할 수 있다. Hopper 아키텍처에서 2세대로 진화한 MIG를 사용하면 기업에서 사용하는 GPU 자원을 완전히 격리된 가상화 환경으로 구성해서 동시에 여러 명의 데이터 과학하자 AI 모델 학습을 시킬 수 있다. 메인 AI 프로젝트에 대부분의 GPU 자원이 사용되고 있어서 이제 막 시작하는 파일럿 AI 프로젝트의 연구를 위해 클라우드 서비스의 AI 인스턴스를 사용할 필요가 없다는 것이다. MIG로 GPU 자원을 나눠쓰면 되니까 말이다.
DPX 명령어

DPX는 Dynamic Programming X의 약자로, 여기서 Dynamic Programming은 동적 프로그래밍, 동적 계획법이라고 번역한다. 동적 프로그래밍은 프로그램이 시간에 따라 동적으로 변하는 것을 의미하며, 하나의 큰 문제를 여러 개의 작은 문제로 나누어서 해결하려는 문제해결 방법이자 알고리즘 설계 기법이다. 큰 문제를 작은 문제로 쪼개서 해결 방안을 찾고, 작은 문제 별 해결 방안을 저장(기억)해 둔 다음 재활용하면서, 거대한 하나의 문제를 해결해 나가는 형태라고 보면 된다.
동적 프로그래밍은 현재 생물학 및 질병 연구, 신약 개발 등 헬스케어에 널리 활용되며 물류 센터 내부를 바쁘게 오고 가는 자율 로봇의 경로 최적화 작업에도 활용되고 있으며, 다수의 데이터가 저장된 테이블을 서로 연결하는 조인 작업을 수행할 때 보다 빠르게 처리되도록 SQL 쿼리를 가속화 시켜준다.
개발자들은 이러한 동적 프로그래밍을 주로 CPU나 FPGA에서 실행해 왔으나 이제 NVIDIA가 제공하는 DPX 명령어를 사용해 동적 프로그래밍 처리 속도를 향상시킬 수 있게 되었다. 특히 Hopper 아키텍처 기반의 DPX 명령어 집합은 이전 세대인 Ampere 아키텍처 대비 동적 프로그래밍 처리 속도가 최대 7배 향상됐다. 덕분에 Hopper 아키텍처 기반의 H100은 LLM 이외에도 앞서 언급한 다양한 분야에서 AI 연구 목적으로 널리 활용될 수 있다.
NVIDIA H100 라인업
NVIDIA H100 폼팩터
NVIDIA Hopper 아키텍처 기반의 GPU, H100은 3가지 폼팩터로 제공된다. PCIe, SXM5, 그리고 NVIDIA CPU인 Grace CPU와 H100 GPU가 통합된 GH100 SXM5다. 아래의 이미지를 보자.

왼쪽부터 가장 서버 마더보드의 PCIe 슬롯에 장착하는 H100 PCIe Gen5, NVIDIA가 개발한 GPU 전용 슬롯에 장착하는 인터페이스인 SXM(Scalable Link Interface (SLI) for PCIe eXternal Module)방식이 적용된 H100 SXM5, 그리고 NVIDIA가 자체 개발한 ARM 기반 프로세서인 Grace CPU와 H100 GPU 칩이 하나의 모듈에 탑재된 GH100 SXM5이다. 각 폼팩터마다 스펙도 다른데, 아래의 표를 보자.

H100 PCIe 대비 H100 SXM이 약 30%정도 성능이 높지만 요구 전력량, TDP는 2배다. 따라서, 충분한 전력을 공급받을 수 있는 IDC라면 H100 PCIe보다 H100 SXM을 선택하면 된다. 하지만 이정도 수준의 전력 공급이 어렵다면 PCIe 폼팩터를 선택하면 된다. PCIe Gen5를 지원하는 범용적인 서버 메인보드에 H100 PCIe 카드를 1개부터 8개까지 원하는 만큼 설치할 수 있는데, 위 표에서 보듯이 SXM 폼팩터보다 성능이 다소 떨어진다. 따라서 보다 전문적인 AI 연구용으로 GPU 서버를 구성할 계획이라면 SXM 폼팩터가 알맞다.
그리고 GH100 SXM의 경우 녹색으로 표시한 부분을 주목하자. GPU 메모리와 메모리 대역폭이 H100 SXM보다 20% 정도 높다. 그리고 가장 큰 특징이 NVIDIA가 자체 개발한, ARM 기반 프로세서인 Grace CPU가 장착되어 있다는 점인데, 이 덕분에 H100 SXM이 탑재된, x86 기반 프로세서인 Intel이나 AMD CPU를 채용한 서버 대비 더 높은 AI 학습 및 추론 성능을 제공하는 것으로 알려져있다.
아무튼, 여기서 기억해야 할 것은 간단하다. H100은 PCIe와 SXM 2가지 폼팩터로 제공되며, NVIDIA Grace CPU와 H100 GPU가 통합된 GH100 SXM이라는, 보다 AI와 HPC 용도에 최적화된 폼팩터가 있다는 것을 기억하면 된다.
NVIDIA H100 NVL

NVIDIA는 지난 2023년 3월 21일에 OpenAI의 GPT-4와 같은 최신 LLM에 최적화된, 새로운 라인업인 H100 NVL을 공개했다. H100 PCIe 폼팩터 카드 2개를 NVLink로 연결해 구성했으며, ChatGPT같은 LLM을 자체적으로 개발하기 위한 AI 인프라인 GPU 서버에 장착되는 GPU 중 가장 강력한 AI 성능을 발휘한다고 알려져있다. 앞서 소개한 H100 PCIe, SXM 폼팩터와 어떻게 다른지 스펙시트로 비교해 보자.

NVIDIA에서 공개한 스펙시트에 따르면, H100 NVL의 성능은 단순히 H100 PCIe 2개를 연결한 것을 뛰어넘는 성능을 보여주고 있다. 기본적으로 성능은 H100 PCIe가 아닌 H100 SXM5의 2배이며 GPU 메모리와 메모리 대역폭, 사용 가능한 MIG 역시 2배다. H100 SXM 폼팩터보다 떨어지는 성능은 딱 하나, H100 PCIe 폼팩터의 한계 상 NVLink 데이터 전송속도가 600GB/s로 H100 SXM5 대비 1/3 떨어진다.
하지만, 주목할만한 것은 H100 NVL의 메모리 용량이다. 1개의 H100 PCIe 카드에 94GB의 메모리를 장착했고, 이걸 2개 붙여서 총 188GB의 메모리를 갖췄다. 이 H100 NVL을 4개 장착해 구성한 서버가 H100 NVL 서버인 것이다. LLM 학습 시 메모리 용량이 많으면 그만큼 한번에 읽어들일 수 있는 파라미터의 수가 늘어난다는 것을 의미한다. 즉, 같은 성능의 GPU라면 메모리 용량이 많을 수록 학습 시간을 단축시킬 수 있다는 얘기다.
그리고 TDP도 중요한데, H100 SXM이 H100 PCIe보다 단일 GPU 기준 성능은 약 30% 더 높지만 TDP는 2배에 달한다. 그런데 H100 NVL의 TDP는 H100 PCIe보다 조금 더 높은 350-400W이며, 한 서버에 장착할 수 있는 GPU 수는 H100 SXM는 최대 8개, H100 NVL은 최대 4개로, 서버의 최대 GPU 성능은 H100 NVL 4개를 장착한 서버가 더 높고 TDP는 3.5배나 낮다.(H100 SXM TDP 700W x 8 = 5,600W vs H100 NVL TDP 400W x 4 = 1,600W) H100 NVL의 전력 효율성이 그만큼 더 좋다는 것으로 해석할 수 있다.

따라서, H100 NVL을 사용하면 H100 PCIe 4개 정도에 요구되는 전력으로 H100 SXM 8개 보다 더 높은 성능을 발휘할 수 있다는 것이 된다. 이는 규모가 아주 크지 않은 IDC에서도 LLM을 위한 가장 뛰어난 성능 + 전력 효율성이 높은 GPU 서버를 운영할 수 있다는 것으로 해석할 수 있다. 상면공간 활용성이 높은 고밀도 GPU 서버 구성이 가능하다는 것이다.
여기까지 NVIDIA Hopper 아키텍처 특징과 H100 라인업에 대해 간단히 살펴봤다. 다음 글에서 앞서 소개한 NVIDIA H100의 스펙을 토대로, 실제 AI 성능이 어느 정도 나오는지 구체적인 벤치마크, 그리고 H100을 탑재한 서버들을 알아보자.
끝!



