
지난 글에서 Intel이 어떻게 AI 가속기 시장에 진입했는지, 현재 AI 가속기 시장을 NVIDIA가 꽉 잡고 있는 이유가 무엇인지 살펴봤다. 이번 글에서는 Intel이 2024년 6월에 발표한 최신 AI 가속기, Gaudi 3가 NVIDIA의 이전 세대 GPU이긴 하지만 여전히 주력 제품인 H100과 비교해 경쟁력이 있는지 따져보자.
Intel Gaudi 3 등장, Gaudi 2에 비해 얼마나 발전했을까?

2024년 6월에 발표된 Gaudi 3는 TSMC 5nm 공정에서 제작되었다. 위와 같이 3개의 폼팩터로 제공된다. 왼쪽부터 살펴보면, HL-325L Accelerator Mezzanine Card는 OEM 파트너들이 제조한 보드에 1개부터 최대 8개까지 장착 가능한 모듈형 구조를 채택한 제품이다. 그리고 가운데에 있는 HLB-325는 인텔이 설계 제조한 보드에 HL-325L 카드 8개가 장착되어, 8개 GPU 세트로 제공되는 제품이고, 마지막 PCIe CEM은 일반적인 서버 보드의 PCIe 슬롯에 꽂아 사용하는 카드로, 최대 4개까지 장착할 수 있다.
중요한 것은, OAM 형태이든 PCIe 형태이든 폼팩터에 따라 성능 차이가 없다는 것이니다. 단지 OAM 폼팩터가 보드 당 최대 8개, PCIe 폼팩터는 보드 당 최대 4개 까지만 사용할 수 있다는 것만 다를 뿐이다. 그래서 단일 시스템에서 소규모로 AI 연구를 수행할 때에는 PCIe 폼팩터가 알맞고, 향후 확장성까지 고려하는 경우라면 OAM 폼팩터가 제격이라고 할 수 있겠다.

Gaudi 2와 Gaudi 3의 스펙을 비교해보자. Gaudi 3는 Gaudi 2와 비교해 HBM 메모리 용량 및 대역폭이 향상됐고 PCIe 5세대를 사용한다. 이러한 향상된 스펙 덕분에 TDP도 600W에서 900W로 증가했는데, 공랭 방식 뿐만 아니라 수랭 방식도 지원해서 높은 발열을 제어할 수 있다.

그럼, 앞서 살펴본 스펙 증가에 따른 성능 향상폭이 어느 정도일까? Gaudi 3는 Gaudi 2에 비해 AI 성능 연산 성능이 FP8 2배, BF16 , 네트워크 대역폭 2배, 메모리 대역폭은 1.5배가 향상됐다. 이러한 스펙 증가에 힘입어 NVIDIA GPU처럼 LLM과 같은 대규모 AI 모델을 처리할 수 있는 성능과 확장성을 갖추게 되었는데, AI 벤치마크 결과는 잠시 후에 보도록 하고, 일단 NVIDIA H100, AMD MI300X와 간단히 스펙부터 비교해 보자.

일단 스펙만 놓고 보면 AMD의 AI 가속기, MI300X가 가장 높다. AMD – Intel – NVIDIA 순이다. AI 성능이 어느 정도인지를 가늠할 수 있는 BF16/FP16 연산 성능(FLOPS) 지표의 경우 NVIDIA와 AMD는 Sparsity 기준 성능 지표를 제공하나 인텔 가우디 3는 Sparsity 연산을 지원하지 않는다. 그래서 명확한 비교는 하기 어려운 것이 아쉽다. 사실, 이번 글의 주제가 AI 연산에 대한 것은 아니고 소보로빵도 데이터 과학자 수준의 지식을 가지고 있는 것은 아니다. 그러니 이 내용은 여기서 마무리하고, 이어서 좀 더 구체적인 성능 지표를 살펴보자.
Intel Gaudi 3 vs NVIDIA H100 AI 성능 비교
지금부터 볼 지표는 모두 Intel 측에서 공개한 것이다. 즉, Gaudi 3에 비교적 유리한 조건에서 테스트한 결과라는 것을 감안하고 지표를 살펴보자. 물론 객관적으로 Intel Gaudi 3가 NVIDIA H100 대비 스펙 상 뛰어나기 때문에 AI 성능이 더 좋은 부분이 있는 것은 사실이다. 그럼에도 불구하고 어쨌든 Intel이 공개한 자료라는 것은 감안해야 한다. 벤치마크이지 않나.
AI 학습 성능 비교: NVIDIA H100 & H200 vs Intel Gaudi 3


Intel의 자료에 따르면, Gaudi 3는 AI 모델 학습 성능에서 NVIDIA H100과 비교해 LLaMa2-7B 모델은 1.5배, LLaMa2-13B 모델은 1.7배, GPT 3-175B 모델은 1.4배 더 빠른 결과를 기록했다. 다수의 GPU, AI 가속기를 연결해 하나의 거대한 클러스터를 구성했을 때에도 Intel Gaudi 3는 NVIDIA H100 대비 더 나은 성능을 보여준 것으로 나타났다.
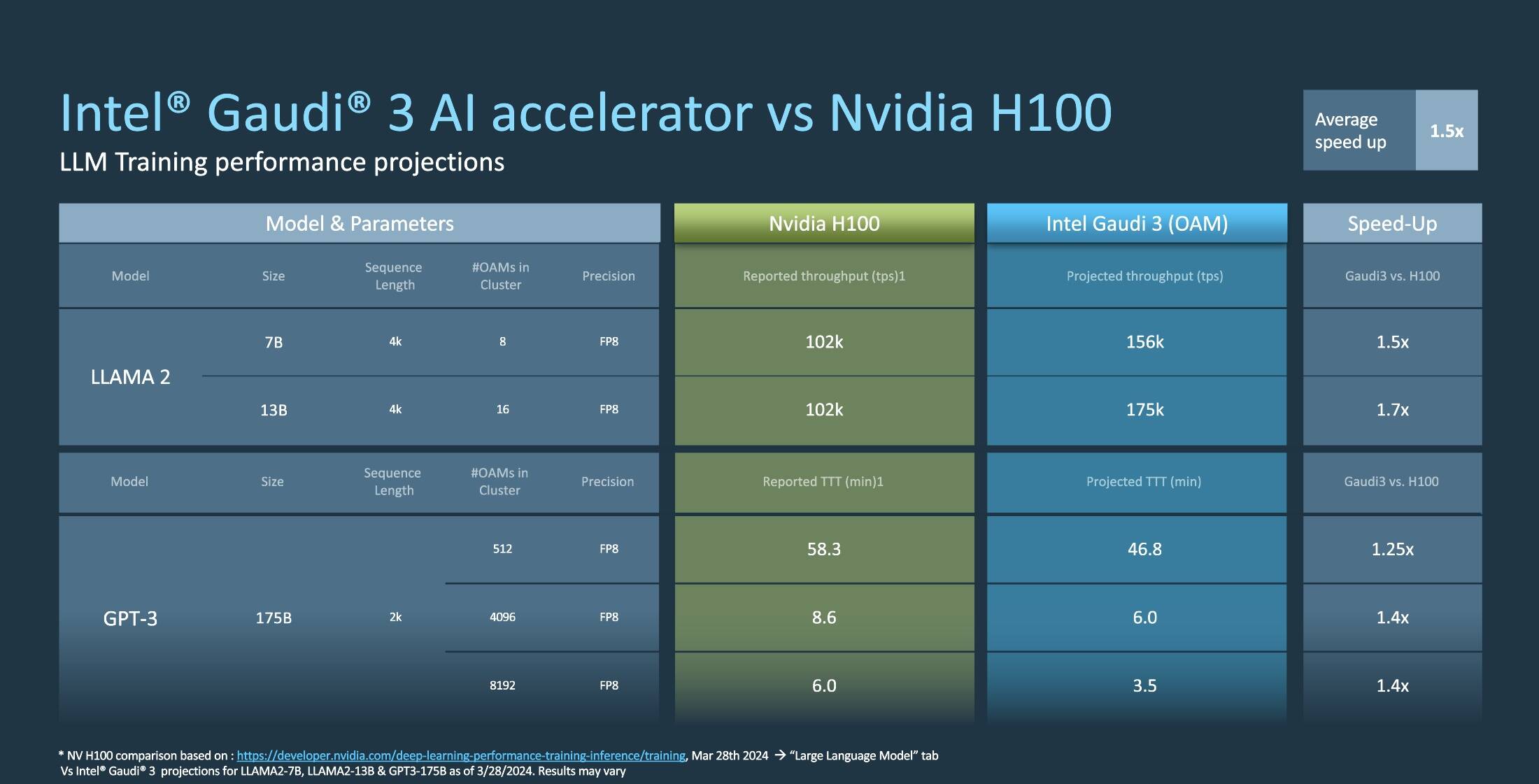
결과를 좀 더 자세히 살펴보자. FP8 형식으로 8개의 Gaudi 3가 장착된 노드 1개, 그리고 16개가 장착된 노드 2개로 AI 모델을 훈련했을 때, Gaudi 3는 NVIDIA H100 대비 LLaMA 2 7B는 1.5배, LLaMA 2 13B는 1.7배나 더 많은 초당 처리량(Throughput)을 기록했다.
그리고 GPT-3 175B와 같이 파라미터 수가 많은 대형 모델에서도 최대 1,024 노드로 8,192개의 GPU를 구성하고 FP8 형식으로 훈련했을 때의 TTT(Time to Train), 모델 훈련에 소요된 시간도 Gaudi 3가 H100보다 1.4배나 더 빨리 학습을 완료한 것을 알 수 있다.
AI 추론 성능 비교: NVIDIA H100 & H200 vs Intel Gaudi 3


이번엔 AI 추론 성능이다. 위와 같이 LLaMA 2 70B 모델에서 Gaudi 3가 H100 대비 1.19배 더 많은 처리량을 기록했고, $당 추론 효율은 2배나 더 높은 결과를 기록했다. LLaMA 3 8B 처럼 더 작은 모델에서도 H100 대비 1.09배 더 많은 처리량에 1.8배의 뛰어난 추론 효율을 보였다. 이 얘기인 즉슨, Gaudi 3의 가성비가 H100보다 더 좋다는 것인데, 비용에 대한 내용은 뒤에서 다시 다루겠다.
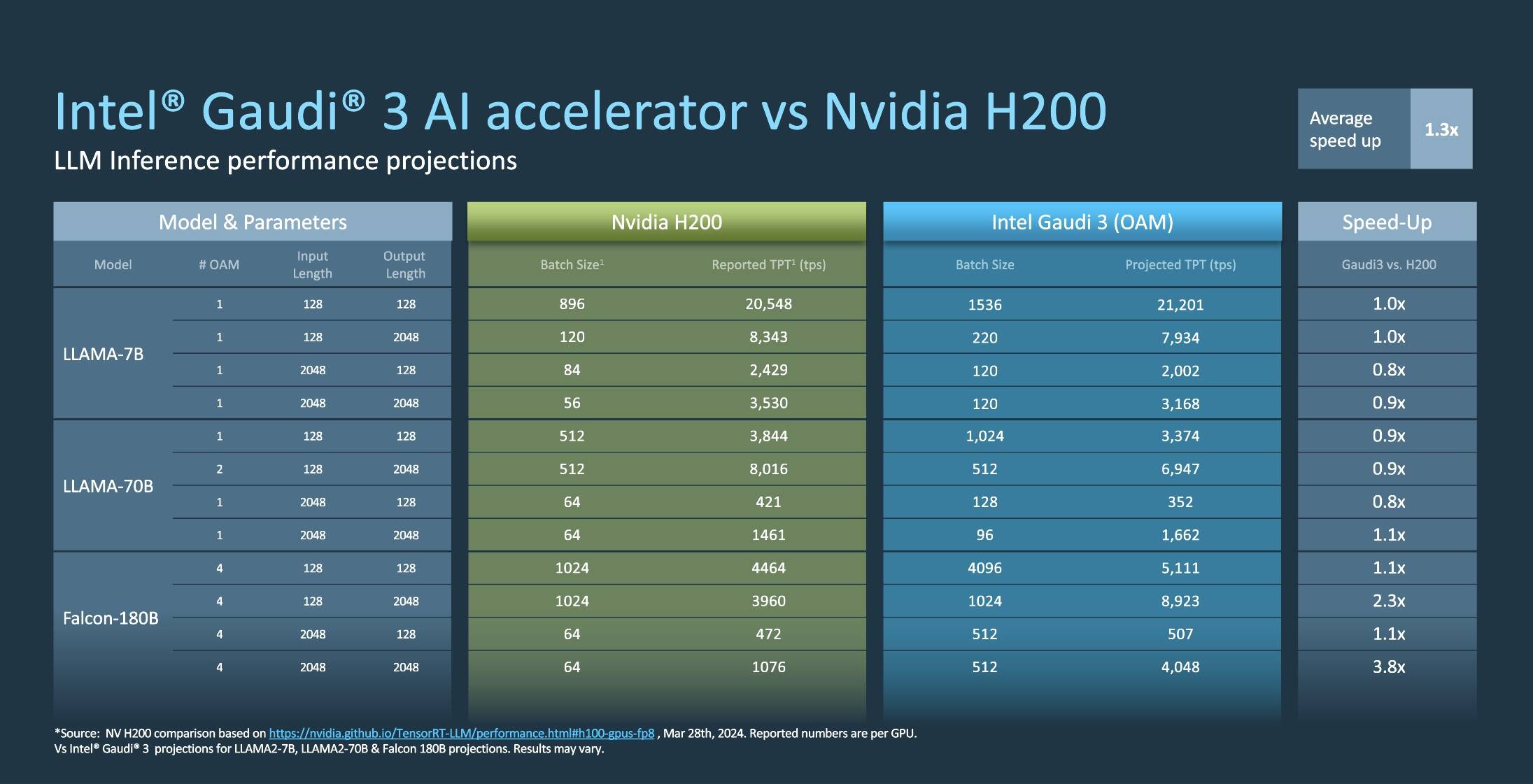
이번엔 NVIDIA H200과의 추론 성능을 비교한 표를 보자. NVIDIA H200은 H100에서 HBM 메모리를 2배 가까이 늘려 141GB의 HBM3를 장착한 제품이다. 메모리가 많으면 한번에 더 많은 양의 데이터를 훈련할 수 있기에 GPT와 같은 대형 모델을 훈련, 학습시킬 때에는 메모리 용량이 매우 중요하다. 비단 학습뿐일까? 추론에서도 많은 메모리가 있으면 더 많은 결과를 내놓을 수 있다. 그런데 Gaudi 3의 HBM 메모리는 128GB로, H200보다 13GB나 적다.그럼, 실제 벤치마크 결과는 어땠을까?
위 표와 같이 8개의 GPU를 장착한 1개 노드 기준으로 LLaMA 7B와 70B의 경우에는 Gaudi 3가 H200 보다 성능이 떨어진다. 하지만 큰 차이가 나지는 않는데, 고무적인 것은 Falcon 180B를 Gaudi 3 4개 노드로 추론했을 때의 결과다. H200보다 2.3배에서 3.8배나 높은 성능을 기록했다. 이정도면 Gaudi 3의 추론 성능은 꽤 훌륭하다고 할 수 있지 않을까?

앞서 본 벤치마크 지표와 같이, NVIDIA H100과 비교해서 오히려 성능 우위를 점하고 있는 Intel Gaudi 3는 위와 같이 단일 노드 구성부터 32 – 64 – 512 – 1,024 노드 구성까지 대규모 클러스터를 구성하더라도 성능이 선형적으로 증가한다. 사실 이렇게 다수의 노드로 대규모 클러스터를 구성하게 되면 성능 향상 폭이 둔화되기 마련인데, Intel Gaudi 3는, 적어도 Intel측의 발표에 따르면 그렇지 않은 것 같다.
이렇게 예상 성능을 예측할 수 있기 때문에 기업은 보다 계획적인 AI 인프라 구축이 가능하다. 활용하려는 AI 모델의 파라미터 수를 기준으로 어느 정도의 학습 및 추론 시간을 목표로 하고 있는지를 정해서 Gaudi 3 기반 클러스터를 구축하면 될테니 말이다. 이는 기업이 AI 인프라 구축 프로젝트 비용을 최적화할 수 있다는 얘기가 된다.
만약, 예상보다 성능이 나오지 않을 경우 노드를 추가해야 하고, 노드를 추가했을 때 예상되는 성능이 가늠이 되지 않으면 얼마만큼의 노드를 추가해야 하는지 판단하기 어렵지 않을까? 몇 십 몇 백 노드 규모의 GPU 클러스터를 구성하는 데에는 수백억 단위의 비용이 소요될 수 있을텐데, 예상 성능을 예측하기 어렵다? 그 프로젝트는 성공적으로 마무리할 수 없을 것이다. 이런 면에서 Intel Gaudi 3의 선형적인 성능 확장은 GPU 클러스터 구축을 준비하는 IT 인프라 담당자 입장에서 아주 중요한 요소가 될 수 있다고 본다.
Intel Gaudi 3는 비용 경쟁력도 괜찮은 편이다

이제 Gaudi 3의 비용 경쟁력을 따져보자. 구체적으로 Intel Gaudi 3는 NVIDIA H100보다 얼마만큼 저렴할까? 2024년 6월 Intel이 발표한 내용에 따르면, Gaudi 3 AI 가속기 8장이 장착된 UBB(Universal Base Board)의 가격은 $125,000으로, NVIDIA H100 GPU 8장을 장착한 HGX 보드와 비교해 2/3 수준이라고 발표했다. 개별 GPU 가격을 환산하면(물론 보드 값이 포함되어 있어 정확한 가격은 아닐테지만) $15,625 정도가 된다. NVIDIA H100 GPU의 단일 가격은 $25,000 내외이고, 신제품 B100 GPU는 $30,000 정도로 알려져있으니 GPU 당 금액은 가우디 3가 H100, B100과 비교해서 절반 정도라고 할 수 있다. Gaudi 3의 가성비가 꽤 좋다.
NVIDIA의 플래그쉽 제품인 GB200의 경우 Grace CPU와 B200 GPU가 합쳐져 대 당 가격이 무려 $60,000 – $70,000에 이를 것이라는 예측되고 있다. Intel Xeon 6 P-코어 프로세서를 다룬 글에서도 살펴봤듯이 Intel Xeon 6 P-코어 프로세서는 AMX 엔진 덕분에 AI 연산 성능이 뛰어나다. 따라서, CPU와 GPU를 최신 Intel 제품으로 구성할 경우 NVIDIA GB200과 비교해서 가성비는 훨씬 좋지 않을까?
자, 이렇게 Intel Gaudi 3의 스펙과 성능, 그리고 비용 경쟁력까지 확인해 봤다. 중요한 것은 Gaudi 3가 H100과 비교해 꽤나 준수한 성능을 보임과 동시에 가격까지 저렴해서 NVIDIA의 대안으로 손색이 없어 보인다. 이런 강점이 과연 AI 가속기 시장에서 통할 수 있을까? 그 가능성에 대해 다음 글에서 좀 더 자세히 다뤄보겠다.
끝!



