
지난 글에서 Intel은 Xeon 6 E-코어 프로세서 외에 또 다른 프로세서를 하나 더 출시했다고 언급했다. 그게 바로 코드명 Granite Rapids, Xeon 6 P-코어 프로세서다. P는 Performance의 약자로, 효율성을 강조한 E-코어 프로세서와는 달리, 이름에서부터 성능에 집중한 프로세서라는 것을 알 수 있다. 그렇다면 E-코어 프로세서와 어떻게 다를까? 하나씩 살펴보자.
Intel Xeon 6 P-코어 프로세서의 기술적 특징

Intel은 데이터센터와 클라우드 환경에서 점점 더 복잡해지 고성능을 필요로 하는 워크로드를 처리하기 위해 Xeon 6 P-코어 프로세서를 설계했다. 코드명 Granite Rapids라는 이름에서도 알 수 있듯이, 이 프로세서는 4세대 Xeon 프로세서 Sapphire Rapids와 5세대 Xeon 프로세서 Emerald Rapids를 계승하고 있다. 그런데, 설계 방식은 많이 달라졌다. 코드명 Sierra Forest Xeon 6 E-코어 프로세서와 마찬가지로, 다수의 코어를 집적하기 위해 연산 유닛과 메모리 컨트롤러 통합한 컴퓨트 다이는 Intel 3 공정에서, I/O 다이는 Intel 7 공정에서 제작되어 패키징했다.

결과적으로 3개의 타일을 집적한 컴퓨트 다이는 최대 128코어를 지원해 이전 세대인 Emerald Rapids의 64코어 비해 코어 수가 2배나 늘었다. 물론 86코어, 48코어, 16코어 등 더 작은 수의 코어를 탑재한 프로세서도 존재한다.

최대 128코어를 지원하는 Xeon 6 P-코어 프로세서 6980P 제품은 기본 클럭 속도 2.0GHz와 최대 클럭 속도 3.9GHz를 지원하며, DDR5-6400 및 MRDIMM-8800 메모리(Multiplexed Rank Dual Inline Memory Modules, 2개의 DDR5 메모리를 하나로 합친 차세대 DRAM) 지원은 방대한 데이터 처리가 필요한 데이터센터 환경에서 충분한 메모리 대역폭을 제공하는 것이 특징이다. 게다가 L3 캐시 메모리도 504MB로 144코어를 지원하는 E-코어 프로세서 6780E 제품의 108MB보다 거의 5배나 많다.
그리고, P-코어 프로세서는 E-코어 프로세서에서 제거되었던 하이퍼스레딩(HT) 기술이 온전히 남아있다. 덕분에 E-코어 프로세서 대비 코어 수가 적은 한계를 극복할 수 있게 되었다. 하이퍼스레딩은 하나의 물리적 코어가 두 개의 논리적 코어처럼 작동하게 함으로써, 스레드 수를 논리적으로 두 배로 확장하는 기술이다. 이 덕분에 P-코어 프로세서는 물리적 코어 수의 부족을 보완하며, 멀티스레드 작업에서 높은 성능에 더해 효율성도 챙길 수 있는 것이다.
사실, P-코어 프로세서와 E-코어 프로세서 사이에는 이런 스펙 차이보다도 더 큰 차이가 존재한다. 바로, P-코어 프로세서에만 있는 AI 내장 가속 기술이다.
Intel Xeon 6 P-코어 프로세서에만 적용된 AI 가속 기술

<이미지 출처: ServerTheHome, Intel Xeon 6 6700E Sierra Forest Shatters Xeon Expectations>
데이터센터 환경은 단순히 코어의 성능 향상만으로는 다양한 워크로드를 효율적으로 처리할 수 없을 정도로 점점 고도화되고 있다. Intel은 이러한 환경 변화에 대응하기 위해 Xeon 6 P-코어 프로세서에 몇 가지 가속 엔진을 탑재했는데, Xeon vs EPYC #1 글에서 4세대 Xeon 프로세서에서 12개의 가속기, 가속 엔진을 탑재했음을 언급했었다. 그 가속 엔진들이 E-코어 프로세서에도 14개나 탑재되어 있다.(2 x DSA, 2 x IAA, 2 x QAT, 2 x DLB, 6 x VMD) 그런데, 이 가속 엔진 외에 P-코어 프로세서에만 있는 AI 연산을 위한 특별한 기능 2개가 더 있는데, 그것이 무엇인지 알아보자.
Intel AMX(Advanced Matrix Extensions)

AMX는 행렬 연산(matrix operations)을 가속화하는 인텔의 명령어 집합으로, 특히 AI와 머신러닝에서 요구되는 대규모 행렬 계산을 최적화하기 위해 설계되었다. 주로 AI 모델 학습과 같은 고성능 컴퓨팅 작업에 사용되는데, AMX는 행렬 곱셈 및 행렬-벡터 연산을 최적화하여, NLP(자연어 처리), 이미지 인식, 딥러닝 모델 학습 등에서 빠른 계산을 도와준다. 행렬 연산은 AI 연산에서 매우 중요한 작업으로, AMX는 이러한 연산을 CPU 내에서 수행할 수 있도록 해서 GPU 의존도를 줄이고 전력 효율성을 높여주는 역할을 하는것이다.
그리고, AMX는 특히 딥러닝에서도 중요한 역할을 한다. 행렬 계산이 많은 작업에서 GPU 없이도 AI 모델 학습을 처리할 수 있기에, AMX는 CPU 내부에서 AI 모델을 학습하면서 속도와 비용 효율성을 높이는 데 아주 중요한 기술이라고 할 수 있다. 그리고 고속 행렬 연산을 통해 CPU에서 많은 계산 작업을 동시에 수행할 수 있어 AI 추론 및 경량 머신러닝의 작업 효율도 높여준다.
이렇게, CPU 차원에서 AI 연산을 도와주는 AMX는 AMD EPYC 프로세서에는 없다. Xeon 프로세서에만 있는, Intel의 고유한 특징인 것이다.
Intel AVX(Advanced Vector Extensions)

AVX는 벡터 연산(vector operations)을 가속화하는 인텔의 명령어 집합으로, SIMD 방식을 통해 여러 데이터를 동시에 처리할 수 있게 도와주는 엔젠이다. AVX는 주로 과학적 연산, 금융 계산, 영상 처리 및 AI 모델 학습 등에서 사용되며, CPU의 병렬 처리 성능을 높이는 데에 주안점을 두고 있다.
게다가, AVX는 딥러닝과 같은 AI 연산에서 벡터화를 활용하여 수천 개의 파라미터를 한 번에 처리한다. 이러한 가속 성능 덕분에 GPU가 없더라도 AI 모델의 훈련이나 추론 과정에서 병렬 처리 성능을 크게 향상시킬 수 있는데, 특히 NLP와 같은 문맥 분석이나 이미지 분류와 같은 비전 작업에서 AVX가 유용하다. AMX와는 달리, AVX는 AMD EPYC 프로세서도 지원한다.

정리하면, AMX는 주로 행렬 연산을 가속화하여 AI와 머신러닝 워크로드에서 높은 성능을 제공하는, 딥러닝 및 대규모 행렬 계산에 최적화된 기술이다. 반면 AVX는 벡터 연산을 최적화하여 과학적 계산, 금융 계산, AI 모델 학습 등 다양한 워크로드에서 높은 성능을 발휘하는 기술이라고 할 수 있다. 이 두 기술은 Xeon 6 프로세서 중 P-코어 프로세서에만 탑재되어 있다. 그래서 P-코어 프로세서가 AI 나 HPC 워크로드에 알맞은 제품인 것이다.
반면 위 이미지와 같이, Xeon 6 E-코어 프로세서는 좀 더 범용적인, 기업에서 운영하는 다양한 내부 시스템 운영, 가상화 기반 클라우드 컴퓨팅 용도에 알맞은 프로세서라고 할 수 있겠다.
간단 비교: Intel Xeon 6 P-코어 vs AMD EPYC 5세대 Turin
그렇다면 Intel Xeon 6 P-코어 프로세서는 AMD EPYC 5세대 프로세서와 비교해서 어느 정도의 성능 우위를 보이고 있을까? 아쉽게도, 모든 면에서 Intel Xeon 이 뛰어나진 않다. 두 프로세서 간에 어떤 차이가 있는지 간단히 짚어보자. 비교를 위해 동일한 코어 수를 가진 제품으로 표를 작성했다.
| 특징 | Intel Xeon 6 6980P | AMD EPYC 9755 |
| 코어 수 | 128코어 | 128코어 |
| 기본/최대 클럭 속도 | 2.0GHz / 3.9GHz | 2.7GHz / 4.1GHz |
| 하이퍼스레딩 | 지원 (256스레드) | 지원 (256스레드) |
| TDP (열 설계 전력) | 500W | 500W |
| L3 캐시 | 504MB | 512MB |
| 메모리 지원 | 최대 3TB | 최대 6TB |
| PCIe 레인 수 | 최대 96레인 | 최대 128레인 |
| 내장 가속 엔진 | AMX, AVX, QAT, DSA 등 | AVX |
- 내장 가속기 차이
Intel Xeon 6 P-코어 프로세서 6980P의 가장 큰 차별화 요소는 바로 내장 가속 엔진이다. AMX, AVX를 비롯해 QAT, DSA와 같은 가속기는 AI 모델 학습 및 추론, 데이터 압축 및 암호화, 대규모 데이터 전송 등에서 고유의 강점을 발휘할 수 있다. 반면 AMD EPYC 5세대 9755는 AVX-512만 지원해서 AMX가 없는 Intel Xeon 6 6980P AI 워크로드 처리에서 불리할 수 있다.
- 클럭 스피드 차이
Intel Xeon 6 6980P의 기본 클럭 스피드는 2.0Ghz에 불과해 AMD EPYC 9755의 2.7GHz보다 느립니다. 부스트 클럭 스피드 역시 AMD EPYC 9755가 4.1GHz로 약간 더 빠르다. L3 캐시 메모리는 둘 다 거의 차이가 없기에, IPC 성능은 AMD EPYC 9755 쪽이 더 뛰어날 것이라고 생각하기 쉽다. 하지만 IPC 성능은 단순히 클럭 스피드에서 판가름 나는 것이 아닌, 실제 프로세서 아키텍처 상 설계의 차이도 있기 때문에 정확한 벤치마크로 비교해야 한다. 하지만 아쉽게도 아직 이 두 프로세서를 비교한 벤치마크 자료는 발견할 수 없었다.
- 메모리 지원과 확장
정성
AMD EPYC 9975는 최대 6TB의 메모리를 지원해서 인텔 제온 6980P 대비 2배의 메모리를 더 장착할 수 있다. 이에 따라 AMD EPYC 프로세서가 데이터베이스 같은 방대한 메모리를 필요로 하는 워크로드에서 더 나은 성능을 보일 가능성이 높다. 게다가 PCIe 5.0 레인도 AMD 쪽이 더 높아 확장성이 더 좋다고 볼 수 있다.
정리하면, 높은 성능을 목적으로 설계된 Intel Xeon 6 P-코어 프로세서 6980P와 AMD EPYC 5세대 Turin 프로세서 9755와의 비교는 보다 복잡한 AI 워크로드 처리에는 Intel이, 범용적인 목적의 워크로드에는 AMD가 유리할 수 있을 것으로 생각된다. 하지만 실제 워크로드 별 벤치마크 결과가 없기 때문에 속단하기는 이르다는 것을 참고하기 바란다.
AI 인프라에 Intel Xeon 6 P-코어 프로세서가 알맞은 이유는?
2023년부터 본격적인 AI 시대에 접어들면서, 데이터센터는 AI와 고성능 연산 워크로드를 얼마나 빨리 처리할 수 있느냐를 매우 중요한 요소로 받아들이고 있다. 이러한 환경에서 Intel Xeon 6 P-코어 프로세서를 단순히 고성능 CPU의 역할을 넘어, AI 기반 워크로드 데이터센터의 중심축으로 자리 잡고자 하는 것이 Intel의 전략으로 보인다. 이러한 전략이 어떤 의미가 있는지 살펴보자.
AI 워크로드 최적화로 GPU 의존도를 낮출 수 있다

AI 워크로드는 일반적으로 GPU에 의존해왔지만, Intel Xeon 6 P-코어 프로세서는 내장된 가속 엔진을 활용해 GPU 의존도를 낮출 수 있다. 앞서 언급했던 AMX(Advanced Matrix Extensions)와 같은 기술은 AI 학습과 추론에서 GPU를 대체하거나 보완하는 역할을 수행하며, 특히 AI 추론과 경량 학습 모델에서 강점을 보이기 때문이다. 그리고 자연어 처리(NLP)와 이미지 인식과 같은 작은 규모의 AI 워크로드에서 GPU 없이도 탁월한 처리 성능을 제공한다고 알려져 있다.
그래서, AMX와 AVX 덕분에, 인텔 제온 6 P-코어 프로세서는 소규모 모델 학습 및 추론에 있어 NVIDIA T4와 같은 엔트리 급 GPU는 충분히 대체할 수 있지 않을까 싶다. 물론 추론 전용으로 개발되고 있는, 최근에 발표되는 다양한 스타트업들과 글로벌 빅테크 기업들의 추론 전용 칩들도 있다. 하지만 이런 칩들은 기존의 매우 고가인 NVIDIA 데이터센터 GPU를 추론 작업에서 만큼은 대체하고자 하는 용도이기 때문에, Xeon 6 P-코어 프로세서 역시 이러한 추론 전용 칩들과 목적은 같다고 할 수 있다. 물론, 추론 전용 칩과 P-코어 프로세서의 AI 추론 성능을 비교한, 공개된 자료를 찾지 못한 점은 아쉽긴 하다.
GPU 의존도를 낮춰 AI 인프라의 비용 절감

GPU는 뛰어난 성능에도 불구하고 높은 비용과 전력 소비로 인해 데이터센터 운영에서 부담이 될 수 있다. Intel Xeon 6 P-코어 프로세서는 이러한 문제를 해결하는 것을 주 목적으로 하며, GPU 대비 상대적으로 낮은 비용과 전력 효율성으로 AI 워크로드를 처리할 수 있는 대안을 제시할 수 있을 것이다.
AI 모델 학습과 추론에서 GPU는 여전히 필수적인 도구로 사용되지만, P-코어 프로세서는 GPU가 처리하려는 AI 워크로드의 특정 부분을 분담하여 GPU 활용 의존도를 낮출 수 있기 때문이다. 예를 들어, AI 학습의 데이터 준비 작업이나 간단한 추론 작업을 P-코어 프로세서가 처리하고 GPU는 대량의 데이터 학습에 집중함으로써 전체 AI 워크로드의 효율성을 향상시킬 수 있다.
그래도, 본격적으로 AI에 활용하기엔 많이 부족한 것이 사실이다


앞서 살펴본 Intel Xeon 6 P-코어 프로세서의 강점이 뚜렷하다 한들, CPU는 어디까지나 CPU다. Intel Xeon 6 P-코어 프로세서가 일반적인 CPU보다 아무리 AI 워크로드 처리 성능이 좋다 하더라도, 데이터센터 GPU보다 병렬 처리 성능, AI 모델 학습 및 추론 성능이 떨어질 수밖에 없다. 태생적으로 CPU는 순차처리 성능이 좋고, GPU는 병렬처리 성능이 좋으니 말이다. 게다가 고성능 데이터센터 GPU의 경우 연산을 담당하는 코어 수가 CPU 코어 수보다 몇십 배 더 많은 수천, 수만 단위로 비교 조차 민망한 수준이다.
물론 코어 당 성능은 CPU가 훨씬 높긴 하지만, 단순 반복 작업이 엄청나게 많이 필요한 AI 모델 학습에는 코어 별 성능이 다소 낮더라도 아주 많은 수의 코어로 동시에 연산을 수행하는 병렬 처리가 핵심이다. 그래서 GPT와 같은 대규모 모델 학습에는 여전히 고성능의 데이터센터 GPU가 필요한 것이라고 할 수 있다.

그런데, 이러한 대규모 AI 모델 학습 및 추론에 활용되는 고성능 데이터센터를 위한 AI 가속기가 Intel에도 있다. 많은 사람들이 AI 가속기 공급 회사로 NVIDIA만 알고 있는 것이 현실이다. 좀 더 이 분야에 관심이 있다면 AMD Instint MI300도 들어봤을거다. 하지만, Intel에도 AI 가속기가 있다. 다음 글에서, AI 가속기에 대한 이야기를 해보겠다.
여기까지 총 3회에 걸쳐 Intel Xeon 프로세서와 AMD EPYC 프로세서를 비교해봤다. 주로 Intel Xeon 프로세서에 대해 다뤘는데, 데이터센터 CPU 시장을 지배하던 쪽이 Intel이고, 매섭게 뒤쫓아오는 쪽이 AMD라 Intel을 주인공으로 내세웠다. 분명한 것은 과거 몇년 동안 Intel의 삽질이 있었고, AMD가 그 기회를 놓치지 않고 제대로 파고들어 현재 거진 7:3까지 AMD가 Intel의 데이터센터 CPU 점유율을 잠식해 나가고 있는 상황인 것은 분명하다.
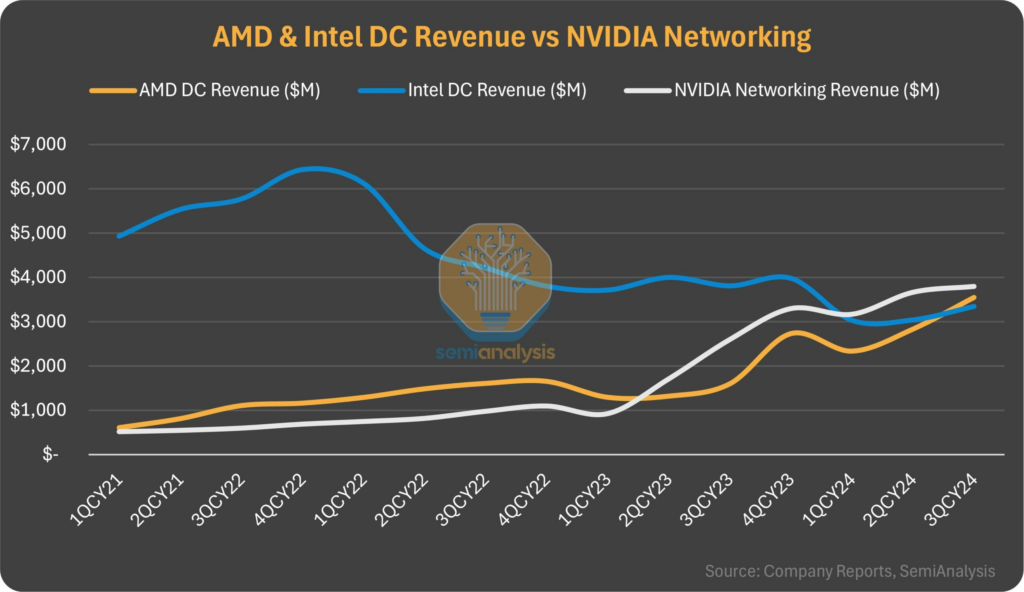
지난 2024년 3분기에 발표된 Intel과 AMD의 데이터센터 부문 실적에 따르면, Intel의 매출은 33억달러, AMD의 매출은 35.5억 달러를 기록해 사상 처음으로 AMD가 Intel을 앞질렀다. 그런데 뭔가 좀 이상하지 않나? 데이터센터 CPU 점유율은 여전히 Intel이 7:3으로 AMD를 엄청나게 앞서고 있다. 그런데 실적이 역전됐다는 것은 두 가지 요인을 생각해 봐야 한다. 하나는 Intel이 AMD의 공습에 맞서기 위해 자사의 프로세서를 매우 저렴하게 공급해서 매출이 줄어든 것, 그리고 두 번째는 AMD의 AI 가속기 매출이 크게 증가한 반면 Intel은 매우 부진했다고 알려져 있다.. 그래서 결과적으로 데이터센터 CPU와 GPU를 모두 포함한 실적에서 AMD가 Intel을 앞지는 것으로 봐야할 것이다.
하지만, 그럼에도 불구하고 Intel의 상황이 매우 암울하냐? 그건 아니다. 물론 상황이 좋지 않은 것은 분명하나, Intel의 전체 매출 비중에서 데이터센터쪽 비중은 25% 정도이고, 우리가 익숙한 데스크탑 PC와 노트북에 탑재되는 컨슈머 용 CPU가 Intel 전체 매출의 60%가 넘는 주력 분야이기 때문이다. 물론 컨슈머 CPU 시장에서도 AMD RYZEN의 공습에 매섭긴 하지만, 데이터센터 CPU 만큼은 아니다.
그럼에도 불구하고 Intel의 상황은 영 별로다. 컨슈머 CPU 시장에서 새롭게 떠오르고 있는 ARM 프로세서도 앞으로 무시 못할 수준으로 성장할 지도 모른다. 다들 Intel의 점유율을 갉아먹으려고 혈안이 되어있다. 다음 글에서 다룰 AI 가속기 시장에서도 Intel의 성과는 영 신통치 못하다. 과연 Intel이 이대로 무너질까? 안그랬으면 좋겠다. 경쟁은 언제나 소비자에게 좋은 것이라고 생각하기 때문이다.
일단 데이터센터 CPU 시장에서 Intel Xeon과 AMD EPYC의 경쟁 구도에 대한 이야기는 이쯤에서 마무리하고, 이어지는 글에서는 AI 가속기에 대한 이야기를 좀 더 해보겠다.
끝!



